KafKa가 생겨난 이유
초기 어플리케이션은 간단한 구조로 이루어져있었습니다.
하지만 급속도로 발전을 하면서 요즘 많이 들리는 MSA 아키텍쳐라고 한번쯤 들어보셨을 겁니다.
여러개의 어플리케이션이 서로 상호작용을 하며 구조가 점점 복잡해졌습니다.
다음 사진과 같이 말이죠.


이후 링크드인에서 카프카라는것을 만들어냅니다. 즉 데이터 흐름(flow)를 한곳에 모아 중앙관리 형태의 구조를 만들어냈습니다.
사진만 봐도 dataflow관점에서 확연한 차이가 나는것을 확인할 수 있습니다.
MQ-메세지 큐
MQ는 들어본사람도 있고 들어보지 못한 사람도 있을겁니다.
Message-Queue라고 하는데, 자료구조에서 Queue형태는 다들 아실거라고 생각합니다.
FIFO(First-In-First-Out)이죠

kafka도 같습니다. MQ형태를 가지고 있는데 이번장에서는 간단하게 소개하고 후에 kafka 구조에 대해 자세히 알아보겠습니다.
파티션: 여기선 그냥 큐라고 생각합니다.
프로듀서: 어떠한 데이터를 생산
컨슈머: 어떠한 데이터를 받음
이렇게 간단하게 생각해볼 수 있습니다.
이러한 형태의 구조가 왜 각광받고 있냐면 프로듀서와 컨슈머의 의존성이 줄기때문입니다.
프로듀서는 파티션(큐)에 데이터를 넣으면 끝입니다.
반대로 컨슈머는 파티션(큐)에 데이터를 받기만 하면 끝입니다.
즉 kafka가 프로듀서, 컨슈머 사이에서 연결역할을 해주면서 프로듀서와 컨슈머 사이의 의존성을 줄여줍니다.
KafKa의 특징
1.높은 처리량
카프카는 프로듀서 컨슈머 모두 배치형태로 데이터를 처리합니다.
만약 데이터를 보낼때마다 네트워크를 연결한다면 리소스 낭비가 심할것입니다.
카프카는 배치형태로 데이터를 보내 네트워크 연결을 최소화합니다.
그렇기에 동일시간내에 더 많으 데이터 처리량을 보여줍니다.
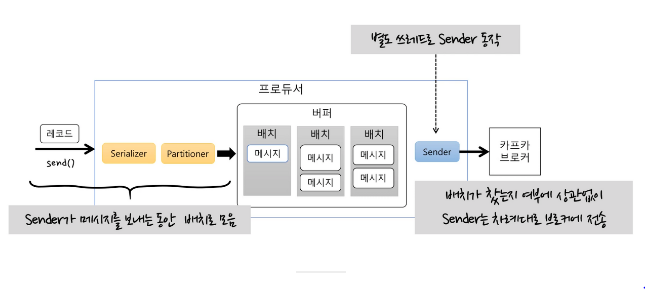
또한 카프카는 파티션에 있는데이터가 한번 컨슘한다고 해서 사라지지 않습니다
이것을 이용하여 컨슈머를 여러개 설정하여 하나의 데이터로 병렬처리를 할 수 있습니다.
2.확장성
카프카는 브로커로 인해 높은 확장성을 가집니다.
그 이유는 카프카 브로커의 개수를 늘리거나(Scale Out), 줄일 수(Scale In) 있기때문입니다.
카프카 브로커는 추후에 설명할 예정이다 확장성 이해를 위해 간단히 소개하겠습니다.

다음과 같이 kafka는 broker를 여러개 둘 수 있는데
쉽게 말해서 병렬처리 + 고가용성 이라고 생각하면됩니다.
복제본을 가질 수 있도록하기위해 여러개의 브로커를 운영합니다.
특히 데이터를 produce/consume하는건 leader라고 적힌곳에서 읽어납니다.
그렇기에 데이터 처리의 부하를 줄여주면서, 고가용성도 유지될 수 있습니다.
3.영속성
카프카는 메모리를 사용하는것이 아닌 파일시스템에 저장합니다.
파일시스템은 비휘발성이기에 영구적으로 저장될 수 있습니다.
파일시스템은 느리다?
-> 카프카는 한번 읽은 파일은 메모리의 캐시데이터로 유지 및 사용하기에 파일시스템을 사용하여도 빠르게 처리 가능합니다.
4.고가용성
2번에서 언급한 내용입니다.
kafka-broker를 통해 복제본을 생성합니다.
만약 1번broker에 장애가 발생하여도 2번 broker가 리더 브로커가 되어 고가용성을 유지할 수 있습니다.
다음글에는 kafka의 전체적인구조에 대해 알아보겠습니다.
'data > kafka' 카테고리의 다른 글
| [KafKa] 카프카 클러스터(Cluster)와 브로커(Broker) (0) | 2022.09.01 |
|---|
